TD5. Séquences de caractères
Le sujet de ce TD est disponible au format pdf ici.
Ce TD a pour objectif de prendre conscience que la notion de complexité a aussi du sens pour l'utilisation mémoire.
Exercice 1 : séquence infinie de caractères
On considère l'analyse d'une séquence de caractères, potentiellement très, très, très longue.
On dispose d'une fonction recupere_prochain_caractere() qui renvoie le prochain caractère non traité de la séquence.
On considère que le caractère @ indique la fin de la séquence.
On cherche à réaliser un ensemble d'opérations d'analyse sur une séquence donnée.
Toutes les opérations doivent être réalisées en une seule passe.
Vous devez donc compléter le code suivant afin de réaliser les analyses des questions 1 à 6.
Le code que nous rajouterons doit uniquement se situer au niveau des ....
Autrement dit, on s'interdit de rajouter du code à l'intérieur de la boucle après la ligne car = recupere_prochain_caractere().
1 2 3 4 5 6 | |
Voici ce que doit être la sortie de notre programme pour la séquence 'a le a pelle nouveaux 23 15 5 faux fi15n5@' une fois que nous aurons réalisé toutes les opérations des questions 1 à 6 :
1 2 3 4 5 6 | |
Question 1
Ajouter le code nécessaire pour compter les a.
Question 2
Ajouter le code nécessaire pour compter les le.
Question 3
Ajouter le code nécessaire pour compter les mots.
Un mot est une suite de caractères quelconques qui se termine par un ou plusieurs espaces ou par le caractère de fin de séquence @.
Question 4
Ajouter le code nécessaire pour compter les mots terminés par x.
Question 5
Ajouter le code nécessaire pour calculer la moyenne de la longueur des mots.
Question 6
Calculer la somme de tous les nombres de la séquence.
Un nombre est l'interprétation en base 10 d'une séquence de chiffres (caractères entre '0' et '9').
Sur l'exemple précédent on obtient ainsi 23 + 15 + 5 + 15 + 5 = 63.
Correction globale
Cliquez ici pour révéler la correction.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 | |
Exercice 2 : mémoire constante, vraiment ?
Question 1
Sommes-nous vraiment certain de ne pas avoir de problème de mémoire ? Pourquoi ?
Correction question 1
Cliquez ici pour révéler la correction.
On peut avoir des problèmes mémoire parce que Python supporte des entiers arbitrairement grands.
Donc les entiers que nous utilisons comme compteurs dans notre programme peuvent devenir arbitrairement grands. Et qui dit entiers arbitrairement grands, dit mémoire arbitrairement grande.
Question 2
En supposant que nous puissions traiter un caractère par nanoseconde (1GHz), combien de temps nous faudrait il pour utiliser 1 kilo octet de mémoire avec une séquence ne contenant que des a ?
Correction question 2
Cliquez ici pour révéler la correction.
Nous allons faire ici des calculs "à la louche" pour calculer des ordres de grandeur et donc faire certaines approximations.
Supposons que notre système soit capable de recevoir un caractère par nanoseconde.
Avec une séquence ne contenant que des a on va donc avoir nombre_de_a qui fait + 1 à chaque nanoseconde.
Pour représenter un entier n en mémoire, il faut \log_2(n) + 1 bits (et même un peu plus dans les langages haut niveau comme Python).
Donc, pour qu'un entier n utilise 1 kilo octet de mémoire (= 1000*8 bits) il faut que n soit égale à 2^{1000*8} + 1.
Pour que nombre_de_a utilise 1 kilo octet de mémoire, il faut donc 2^{1000*8} + 1 nanosecondes.
Si on ramène ce nombre en années en divisant par 10^{9} * 3600 * 24 * 365 on obtient environ 5.5 * 10^{2391}, soit un bon bout de temps.
Il semblerait que nous soyons tranquilles concernant la mémoire avec notre analyse de séquence.
Question 3
Écrire un programme qui sature la mémoire petit à petit de façon visible simplement avec un seul entier.
Correction question 3
Cliquez ici pour révéler la correction.
Nous l'avons vu, il faut grossir beaucoup plus vite qu'en faisant += 1 sur un entier dans une boucle, aussi rapide soit elle.
Allons y donc plus fort :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 | |
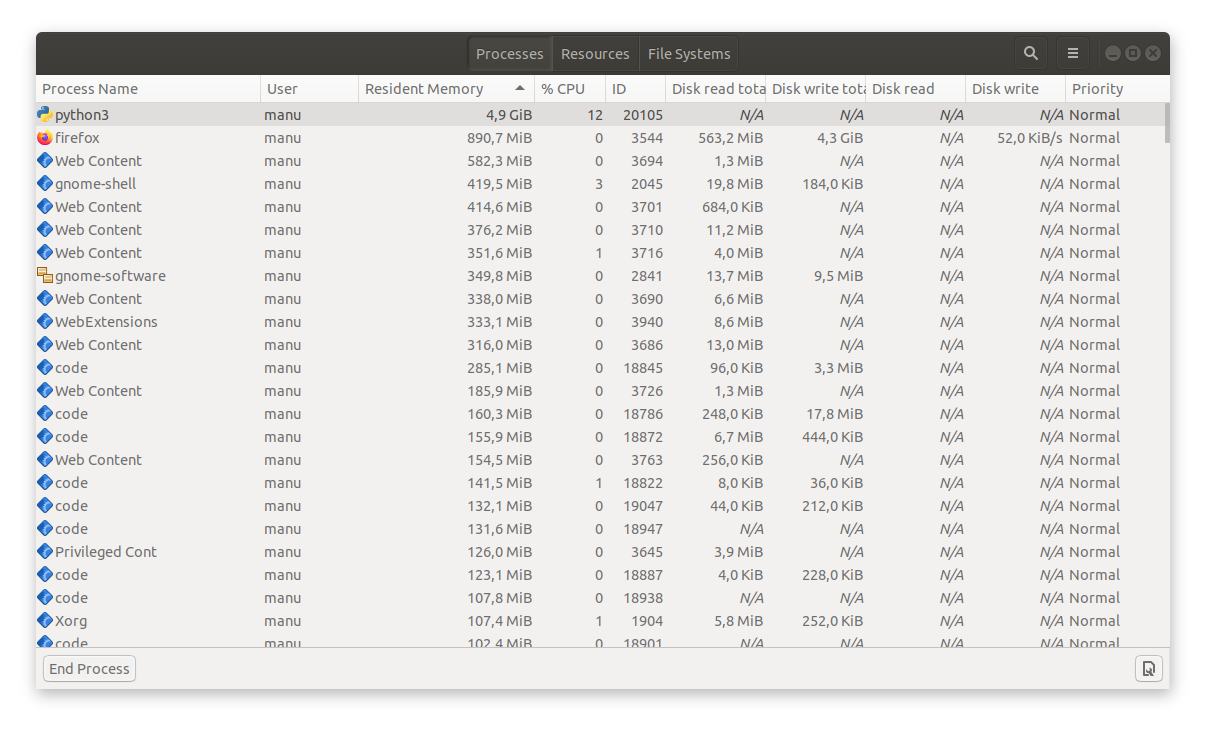
Comme montré sur l'image ci-dessous, on utilisera le moniteur système de notre système d'exploitation pour voir à quelle vitesse l'utilisation mémoire de notre processus Python grossit. Ici on voit que le processus Python utilise 4,9 GiB de mémoire (il tourne depuis environ 30 secondes).
Exercice 3 : mais comment est-ce possible ? (pour aller plus loin)
Question 1
Comment l'interpréteur Python fait-il pour avoir des entiers arbitrairement grands alors que sur une machine 64 bits, le processeur supporte les opérations sur les entiers uniquement si ces derniers tiennent sur 64 bits ?